[1] "Hello world!"ggplot2’ye Giriş
Neden Veriyi Görselleştiriyoruz?
Neden Veriyi Görselleştiriyoruz?
Veri görselleştirme bir süsleme değil; analitik bir araçtır.
İnsan zihni, tablo veya sayı okumak için değil, görsel alanda (doğada) örüntü tanımak için optimize edilmiştir.

Aferin!

Gelir Nasıl Dağılmış?
Sürekli bir değişkenin dağılımı
Histogram
earnings adlı veri setimi al,
Bir görselleştirme yapmak istiyorum, veri setimi al ve ggplot uygula.
Elde edeceğimiz şey boş bir kâğıt parçası olacak. Çünkü henüz eksenlerimizi belirtmedik.

Gelir Nasıl Dağılmış?
Sürekli bir değişkenin dağılımı
Histogram
Elle çizmeye benzer şekilde önce x ve y eksenini çiziyoruz. Bunu R ile yapmak için aes(x = {değişken adı}) fonksiyonunu kullanıyoruz. Ve bunu mevcut boş sayfamıza + sembolü ile ekliyoruz.
+ her zaman satırların sonunda olacak.
Histogramlar için yalnızca x değişkeninin adını vermemiz yeterli; R her gözlemi kendisi sayacak ve y ekseninde gösterecek!
Gelir Nasıl Dağılmış?
Sürekli bir değişkenin dağılımı
Histogram
Gelir Nasıl Dağılmış?
Sürekli bir değişkenin dağılımı
Histogram

Gelir Nasıl Dağılmış?
Sürekli bir değişkenin dağılımı
Histogram
Önce görselleştirmemize bir tema ekleyerek bu berbat grafiği düzeltmeye başlayalım. theme_{tema adı} ile bir tema kullanabiliriz. theme’in her zaman son satırda olduğundan emin olun.
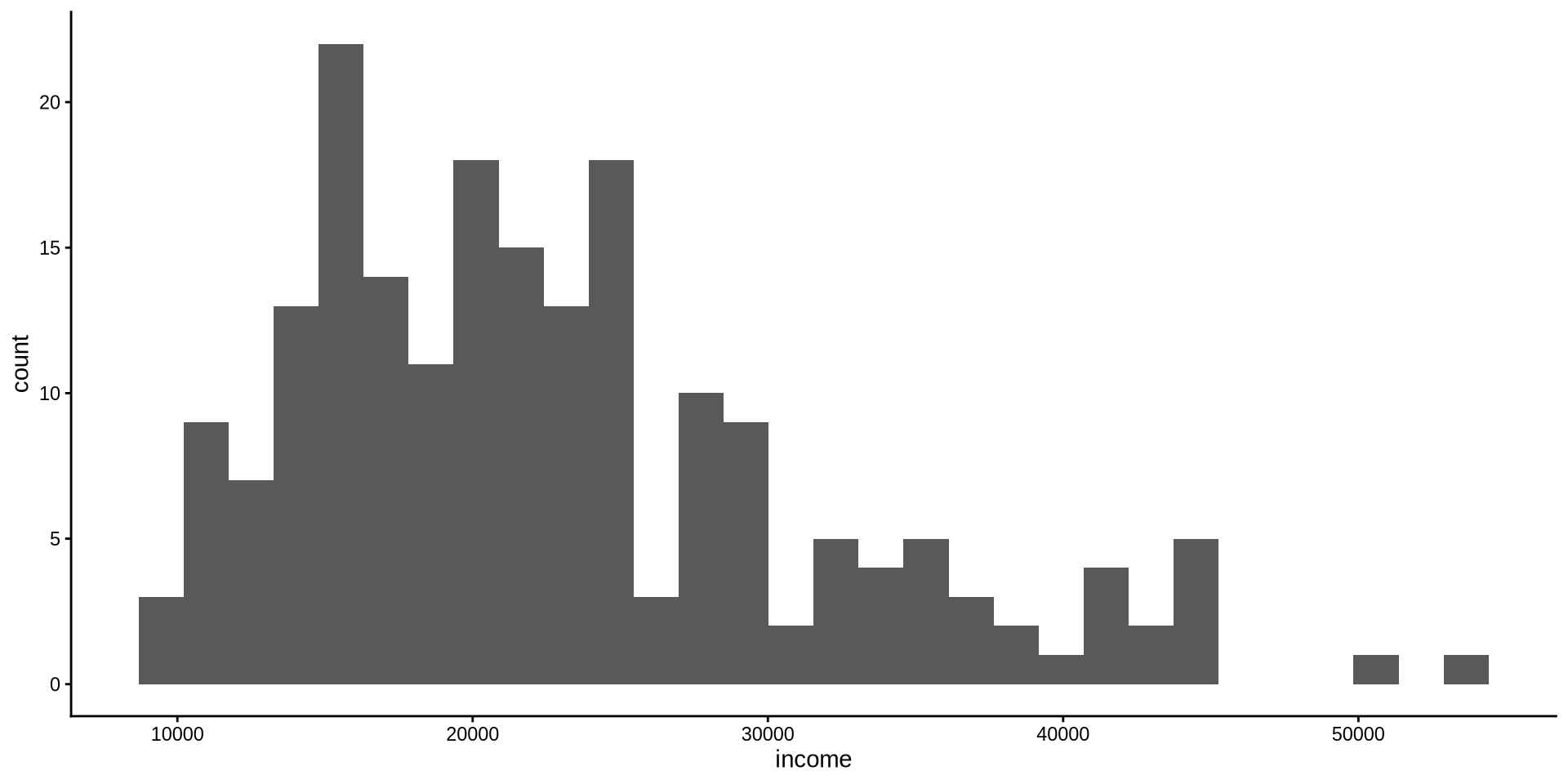
Gelir Nasıl Dağılmış?
Sürekli bir değişkenin dağılımı
Histogram
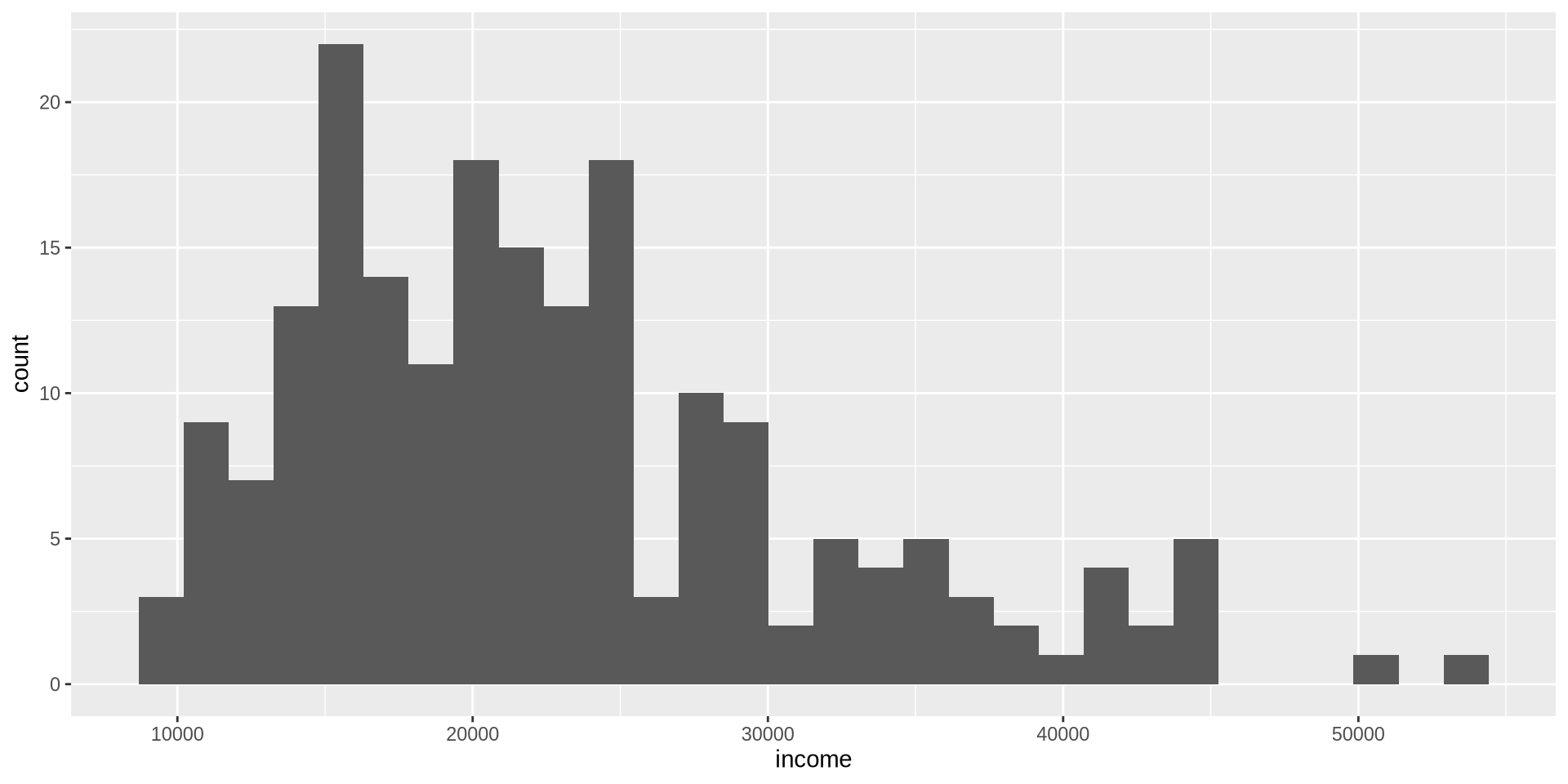
Varsayılan olarak R, geom_histogram() içinde bir bin genişliği seçiyor; bunu görmesek de geom_histogram(binwidth = bir sayı) şeklindedir. Bin genişliğini istediğimiz değere değiştirmek istiyoruz: binwidth=1000
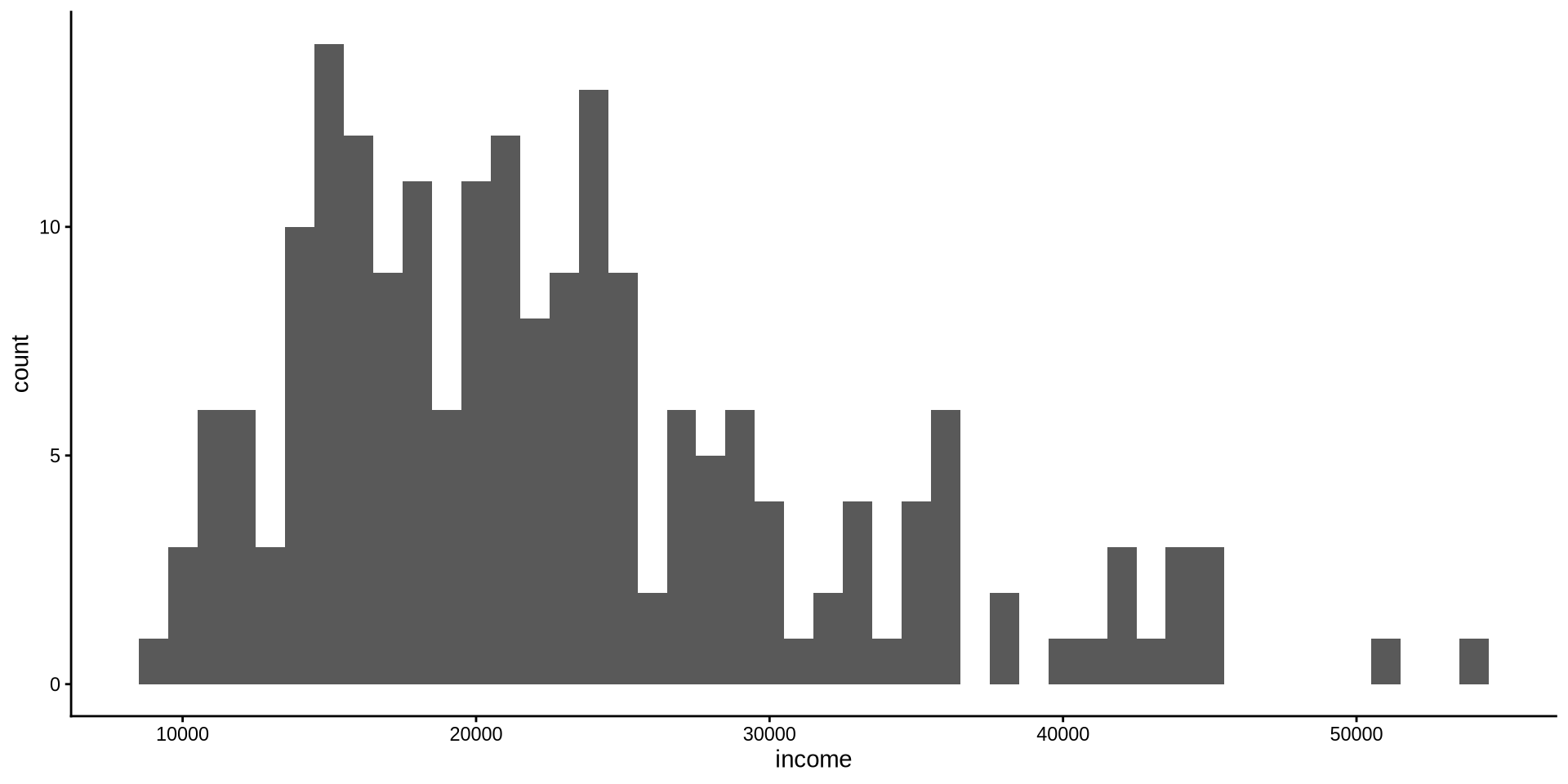
Gelir Nasıl Dağılmış?
Sürekli bir değişkenin dağılımı
Histogram
R ayrıca binleri hangi renkle dolduracağını da otomatik seçiyor. Doldurma (fill) rengini lightskyblue olarak değiştirmek istiyoruz; bunu geom_histogram(binwidth = 1000, fill={"renk adı"}) ile yapıyoruz.
Her argümanı birbirinden ayırmak için , kullandığımıza dikkat edin.
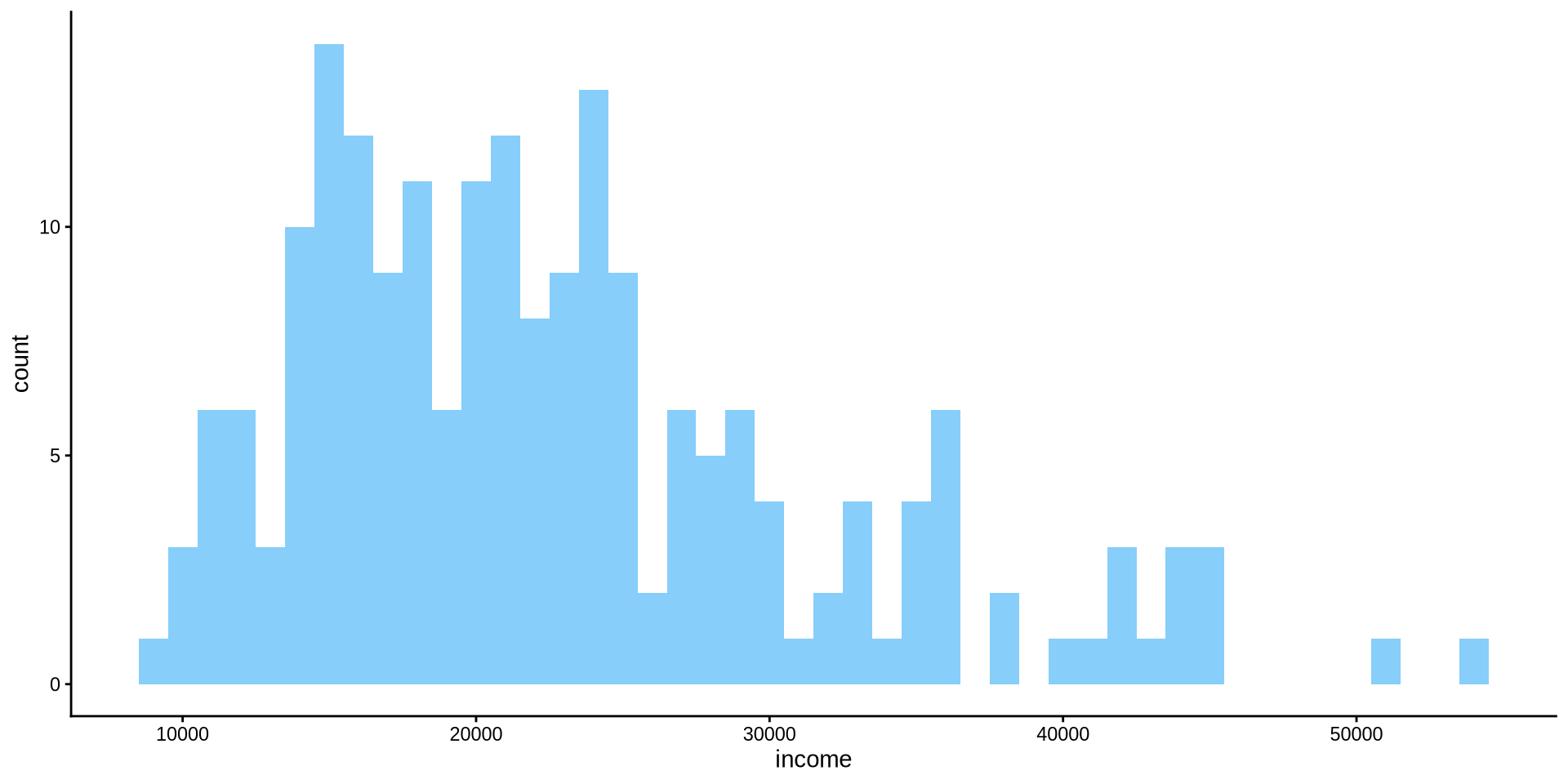
Gelir Nasıl Dağılmış?
Sürekli bir değişkenin dağılımı
Histogram
Binlerin kenarlarının rengini değiştirmek için geom_histogram() içinde color={renk adı} argümanını kullanıyoruz. black yapalım.
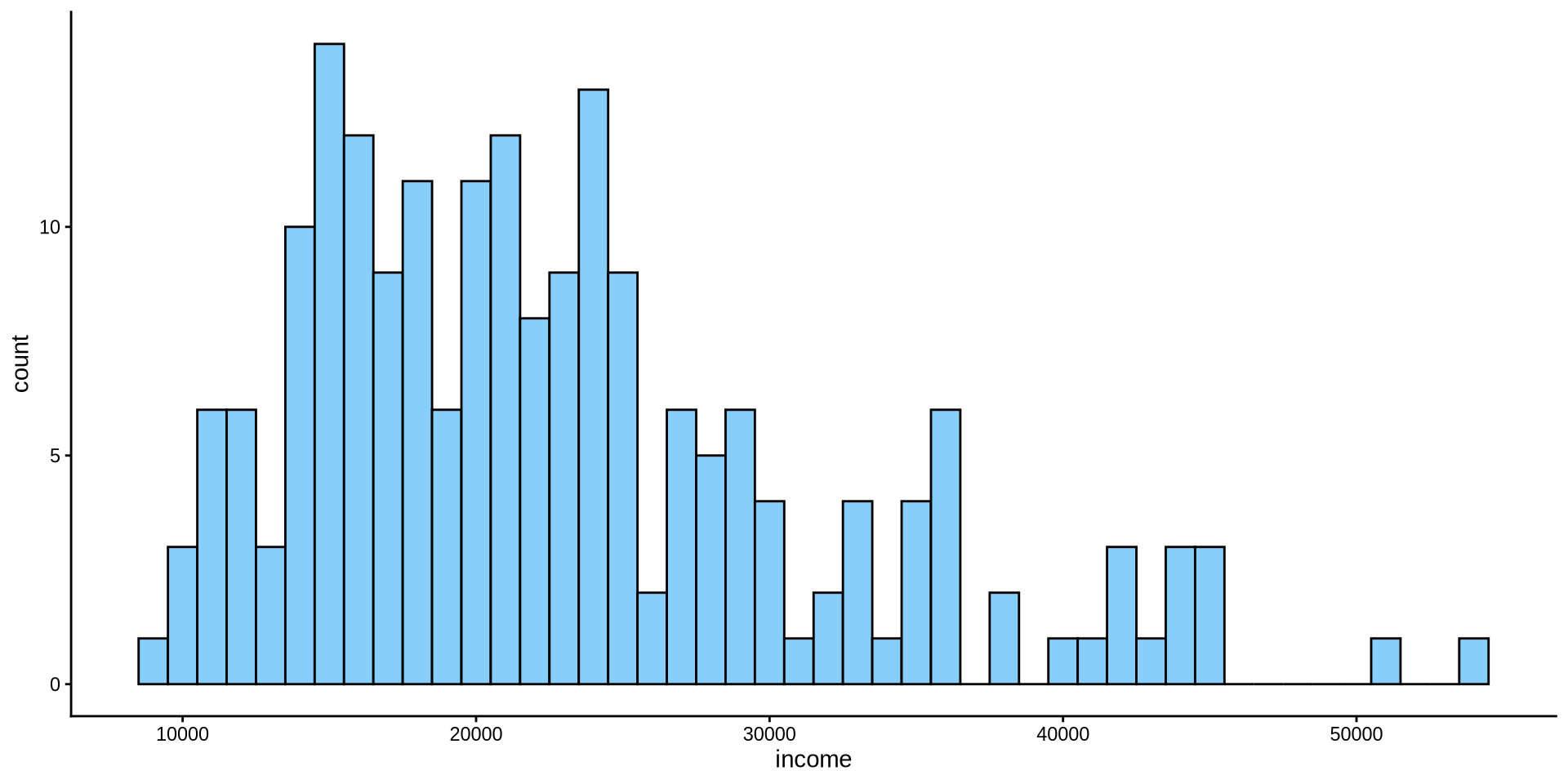
Gelir Nasıl Dağılmış?
Sürekli bir değişkenin dağılımı
Histogram
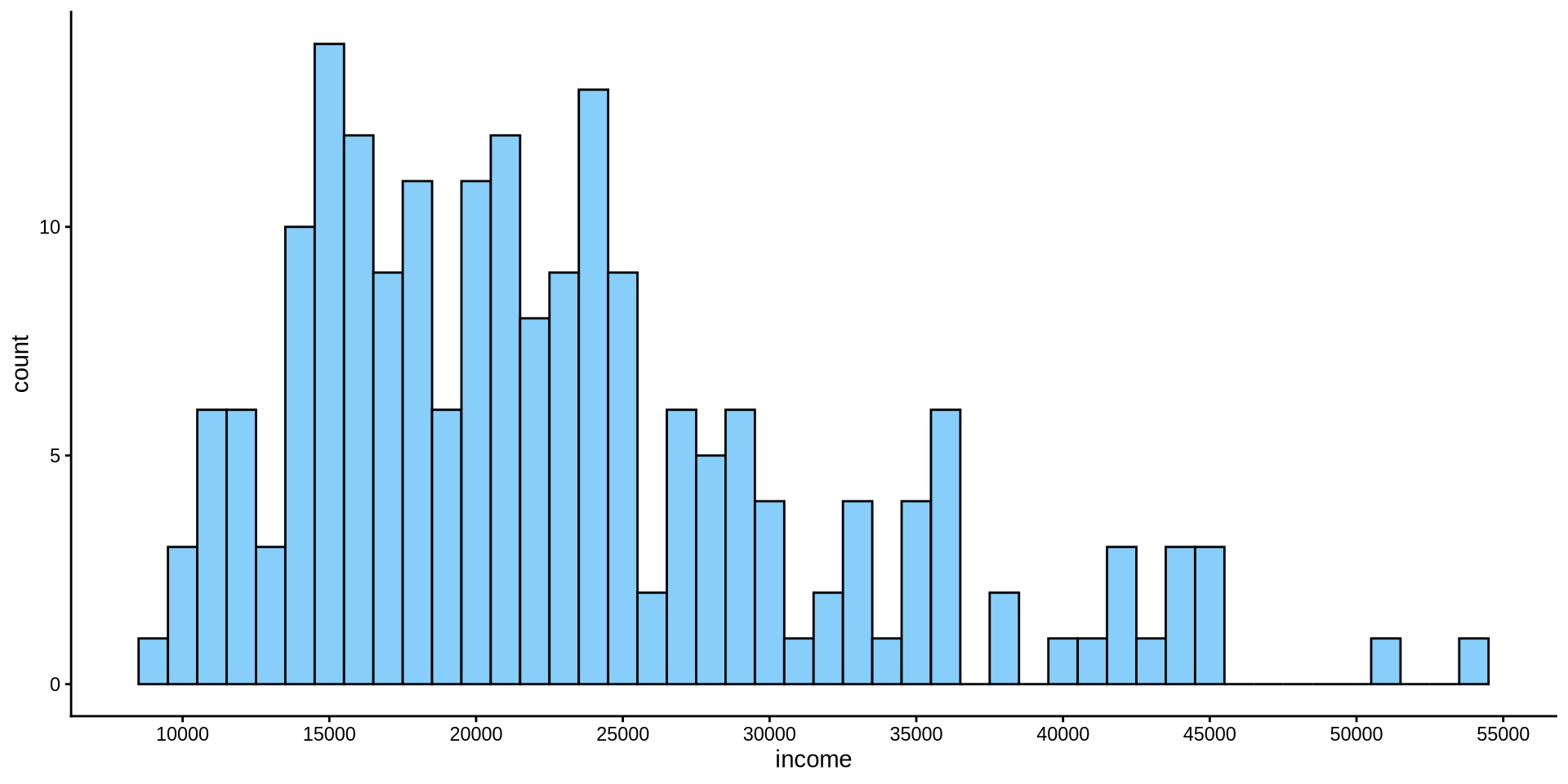
Gelir Nasıl Dağılmış?
Sürekli bir değişkenin dağılımı
Histogram
y ekseninde de aynı sorun var.
y eksenindeki değer sayısını nasıl artırabiliriz? x ekseni için fonksiyon scale_x_continuous(n.breaks=10) idi. y ekseninde kırılma sayısını 10 olarak ayarlayabilir misiniz?
scale_y_continuous(n.breaks =10)
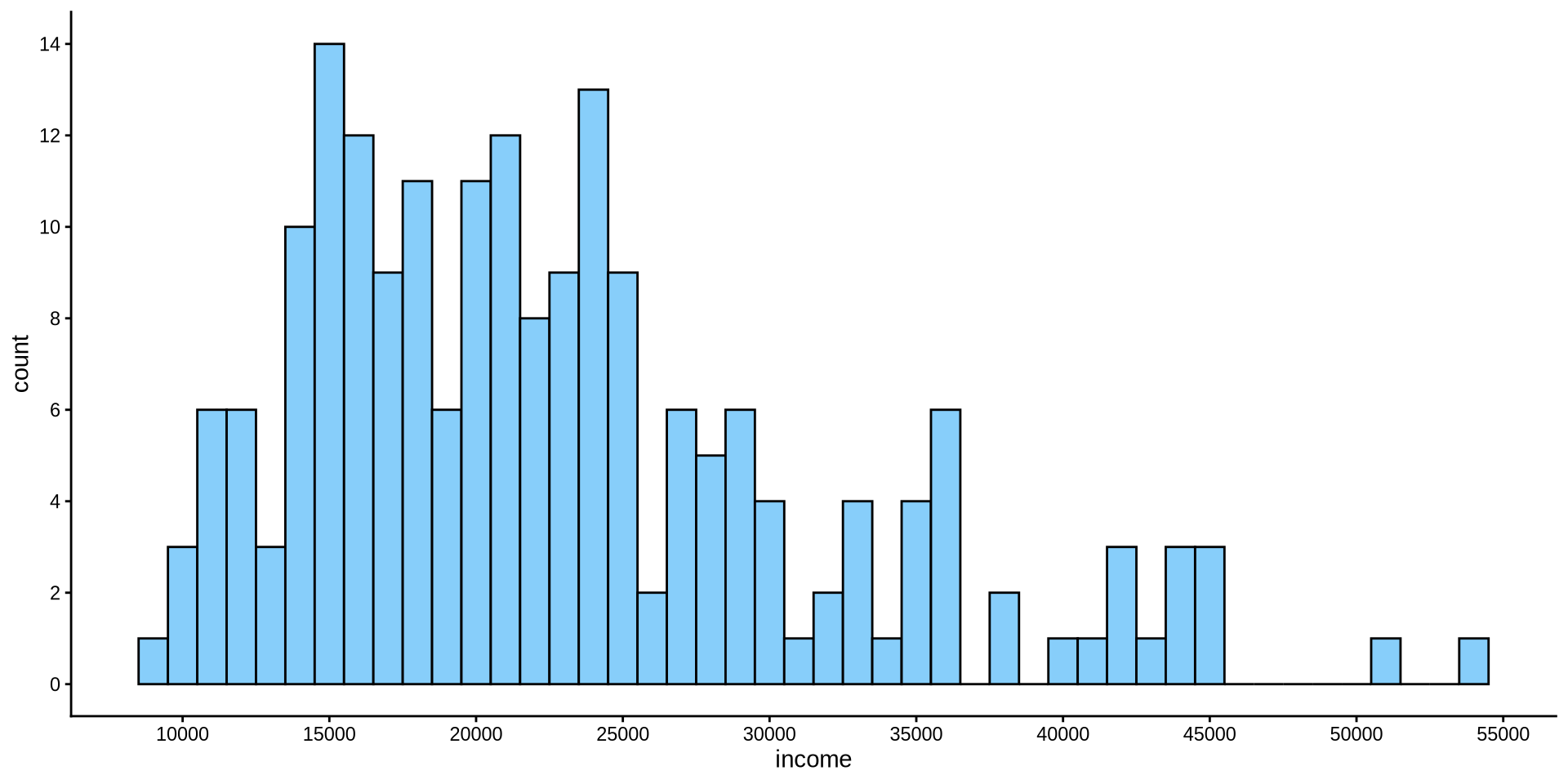
Gelir Nasıl Dağılmış?
Sürekli bir değişkenin dağılımı
Histogram
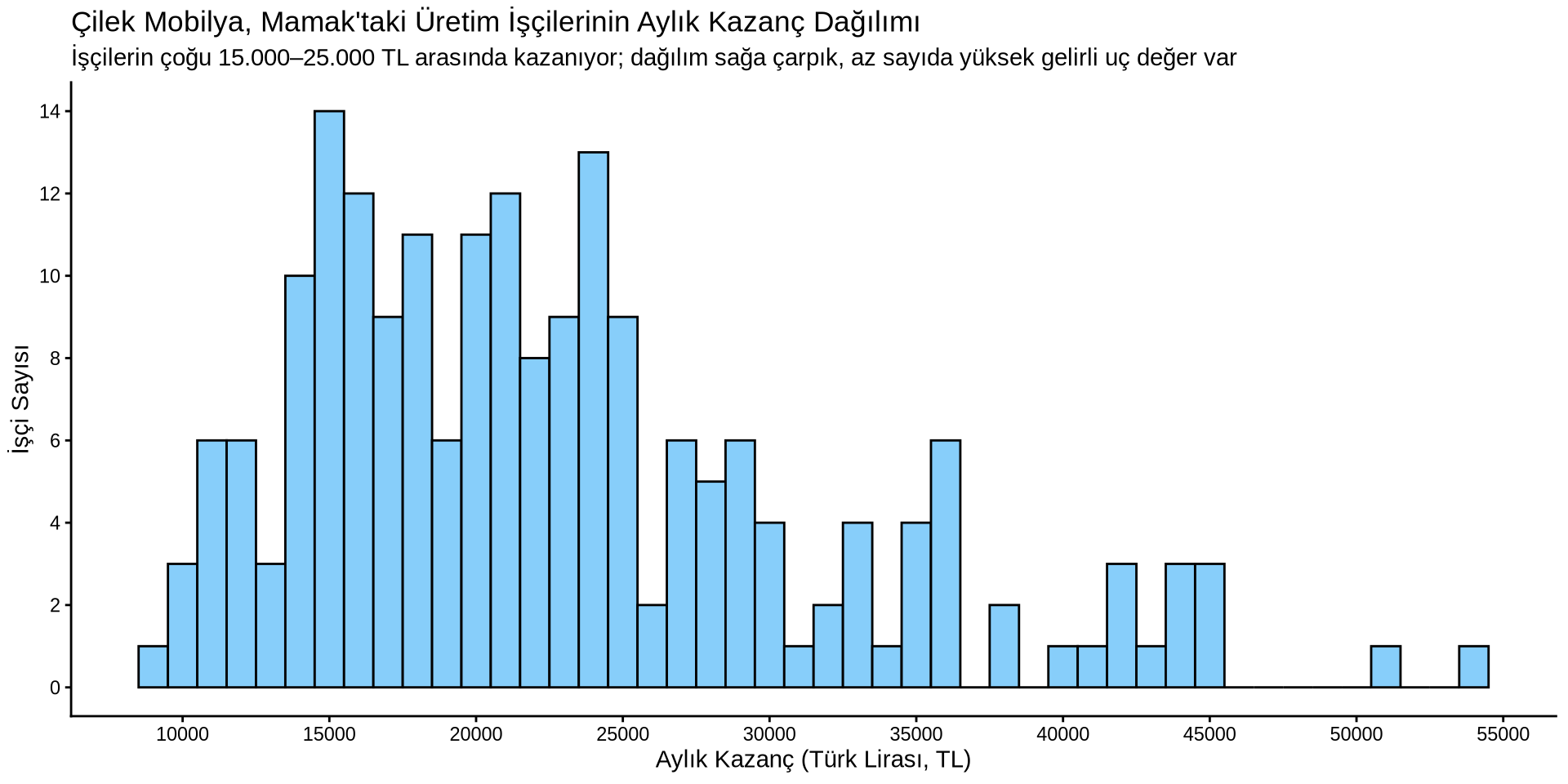
Gelir Nasıl Dağılmış?
Sürekli bir değişkenin dağılımı
Yoğunluk Grafiği
- \[ f(x) = \frac{1}{\sigma \sqrt{2\pi}} \exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right) \]
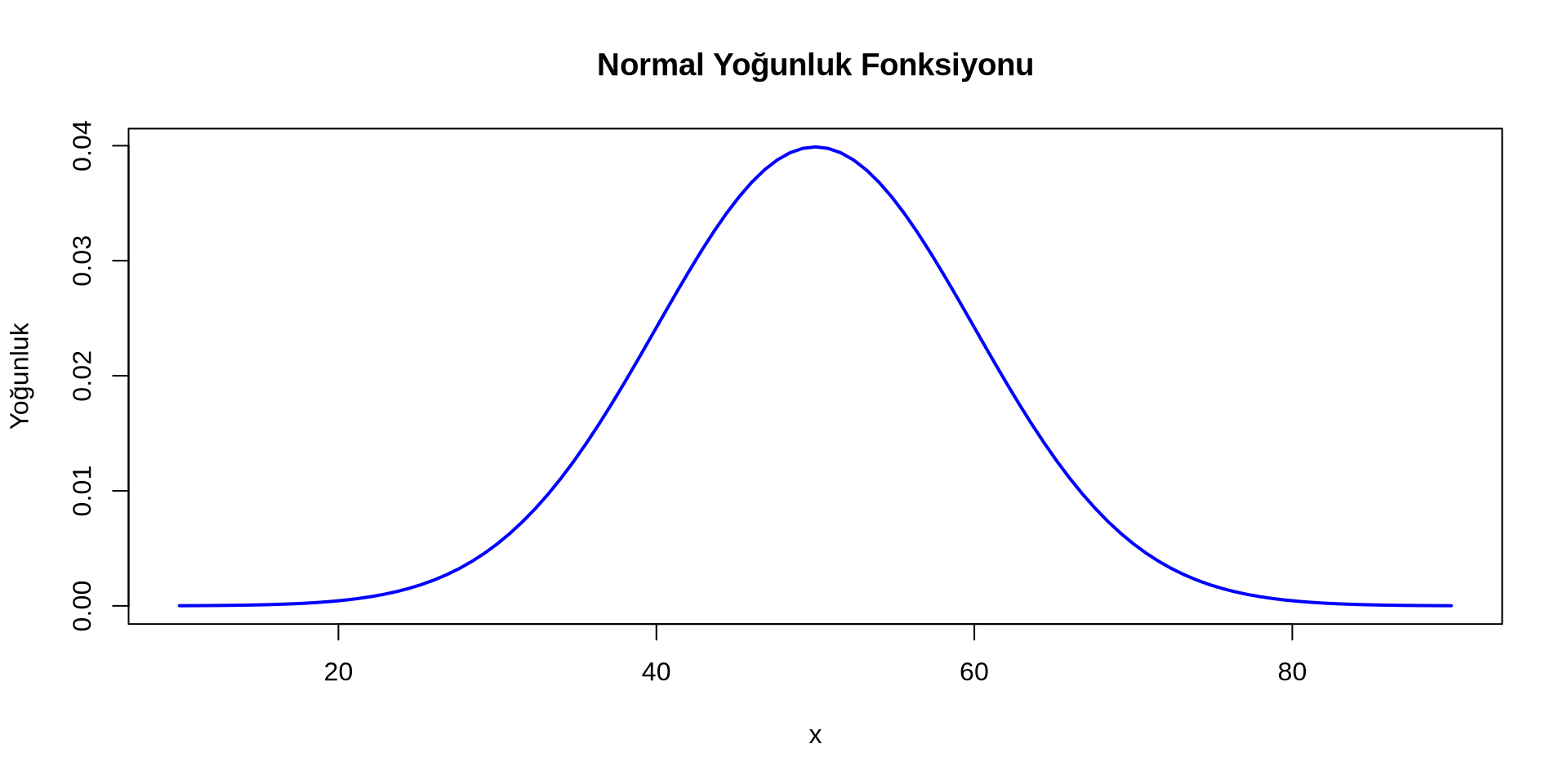
Gelir Nasıl Dağılmış?
Sürekli bir değişkenin dağılımı
Yoğunluk Grafiği
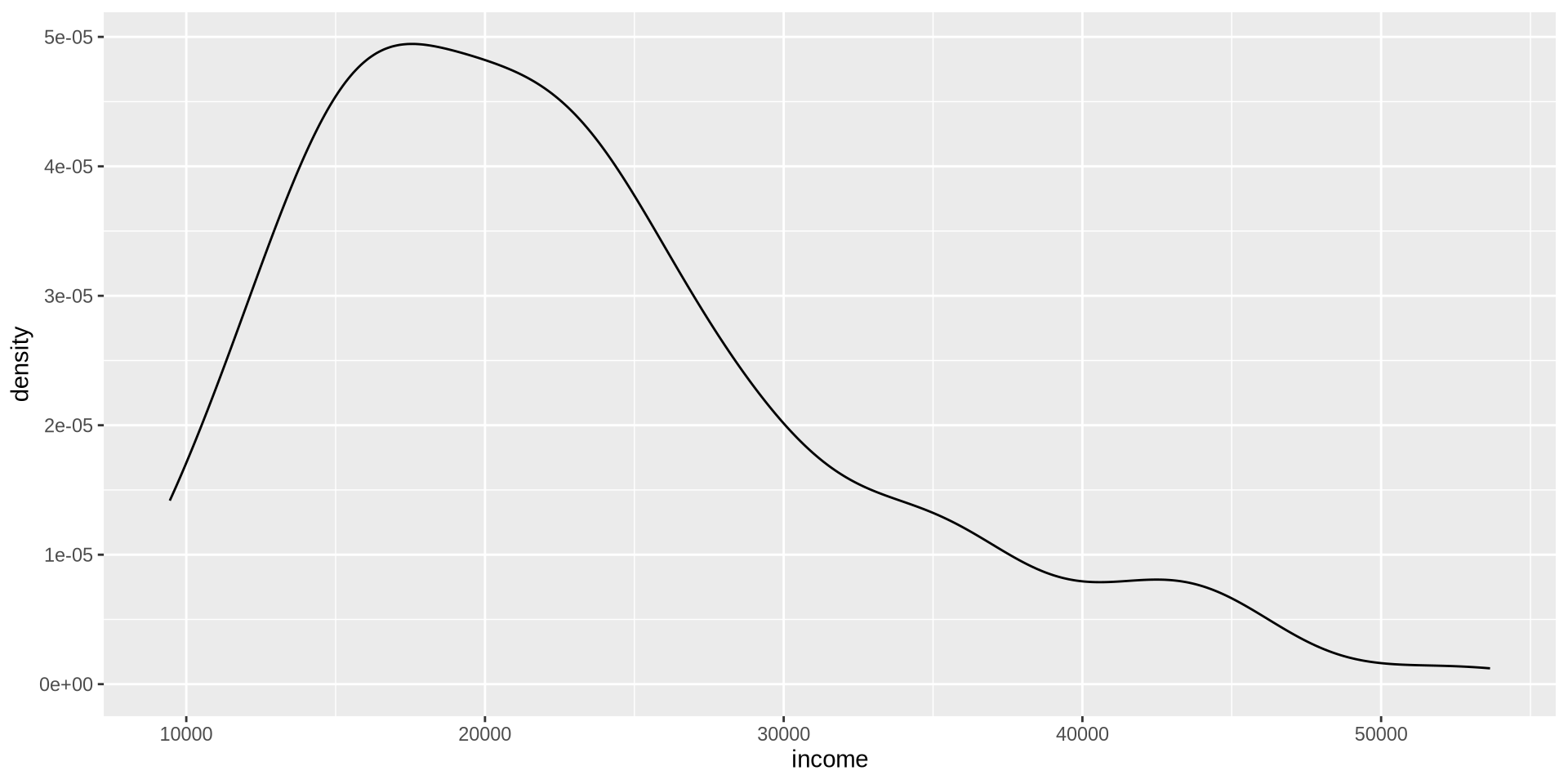
Gelir Nasıl Dağılmış?
Sürekli bir değişkenin dağılımı
Yoğunluk Grafiği
Gelir Nasıl Dağılmış?
Sürekli bir değişkenin dağılımı
Yoğunluk Grafiği
theme_ yazmaya başlayın; sağ taraftaki öneriler arasında ggthemes’i göreceksiniz; oradan bir tane seçin.
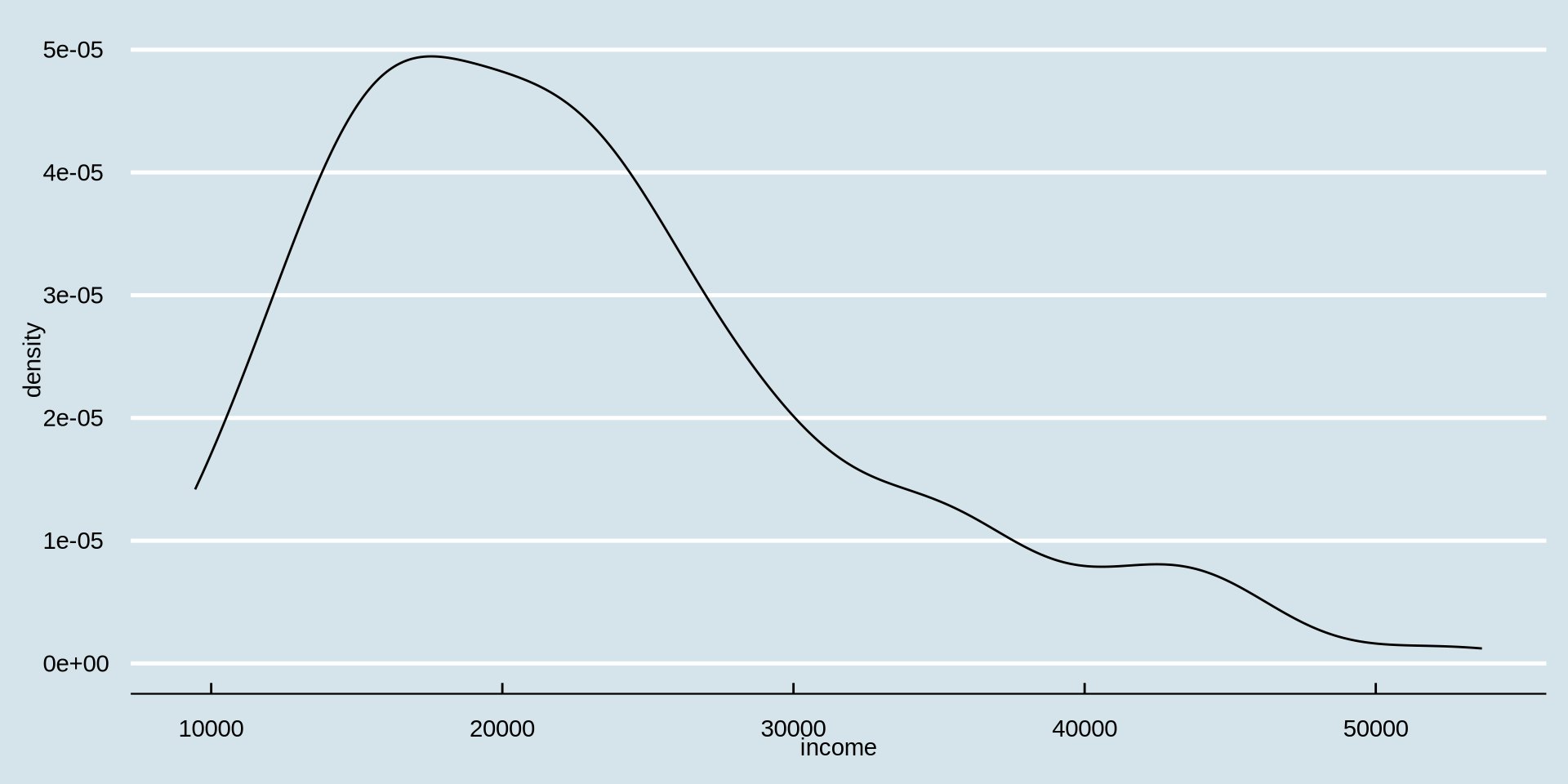
Gelir Nasıl Dağılmış?
Sürekli bir değişkenin dağılımı
Yoğunluk Grafiği
Yoğunluk çizgisinin siyah rengini beğenmedim. geom_density(color = {"tercih ettiğiniz renk"}) içindeki color argümanını kullanarak “azure4” olarak değiştirelim
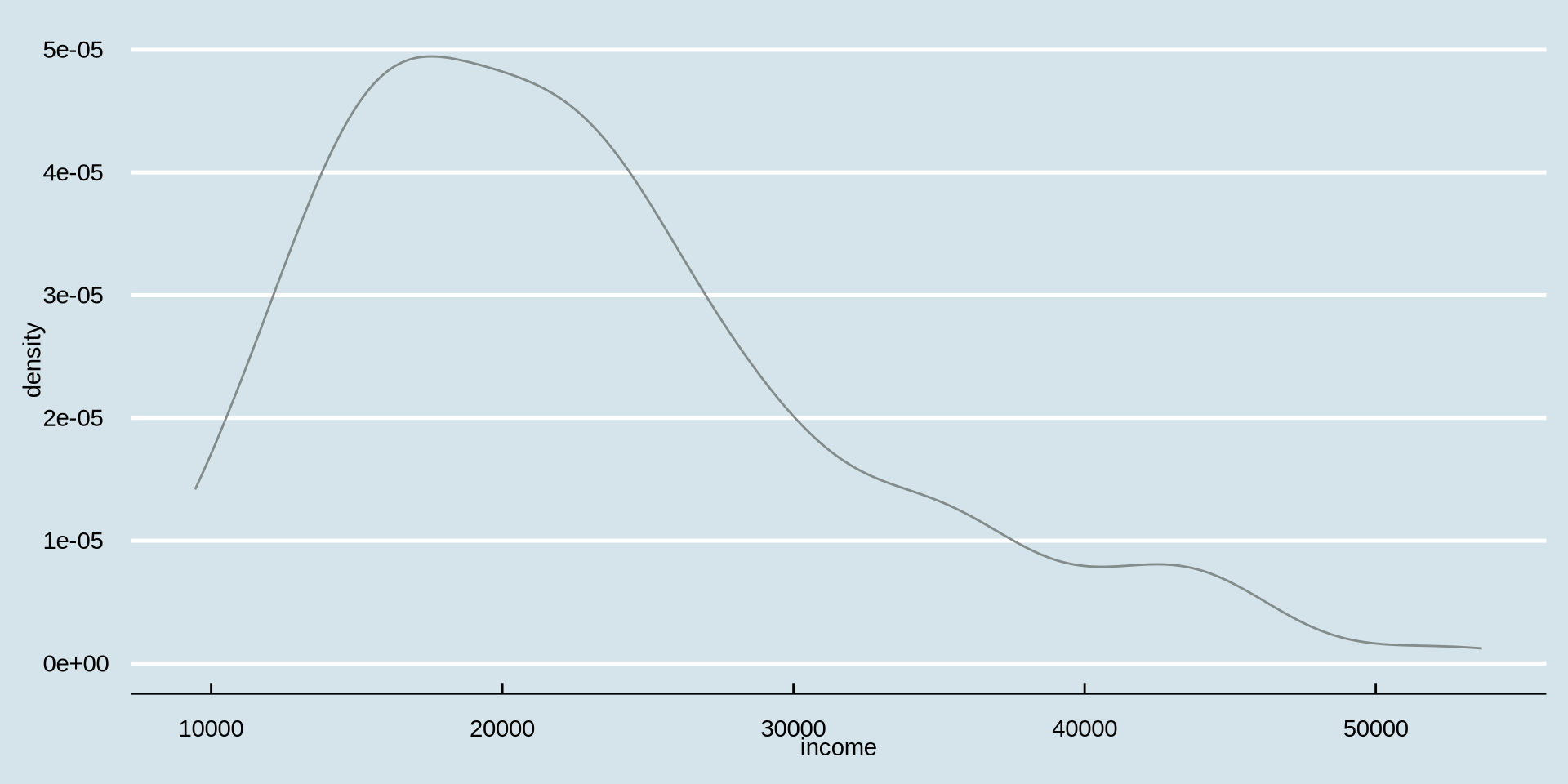
Gelir Nasıl Dağılmış?
Sürekli bir değişkenin dağılımı
Yoğunluk Grafiği
Çizginin kalınlığı biraz ince görünüyor; geom_density() içindeki linewidth argümanıyla artırabilir miyiz? Varsayılan olarak R geom_density(linewidth = 1) şeklinde otomatik olarak ayarlamış.
geom_density(color = {"tercih ettiğiniz renk"}, linewidth = {tercih ettiğiniz genişlik sayısı})
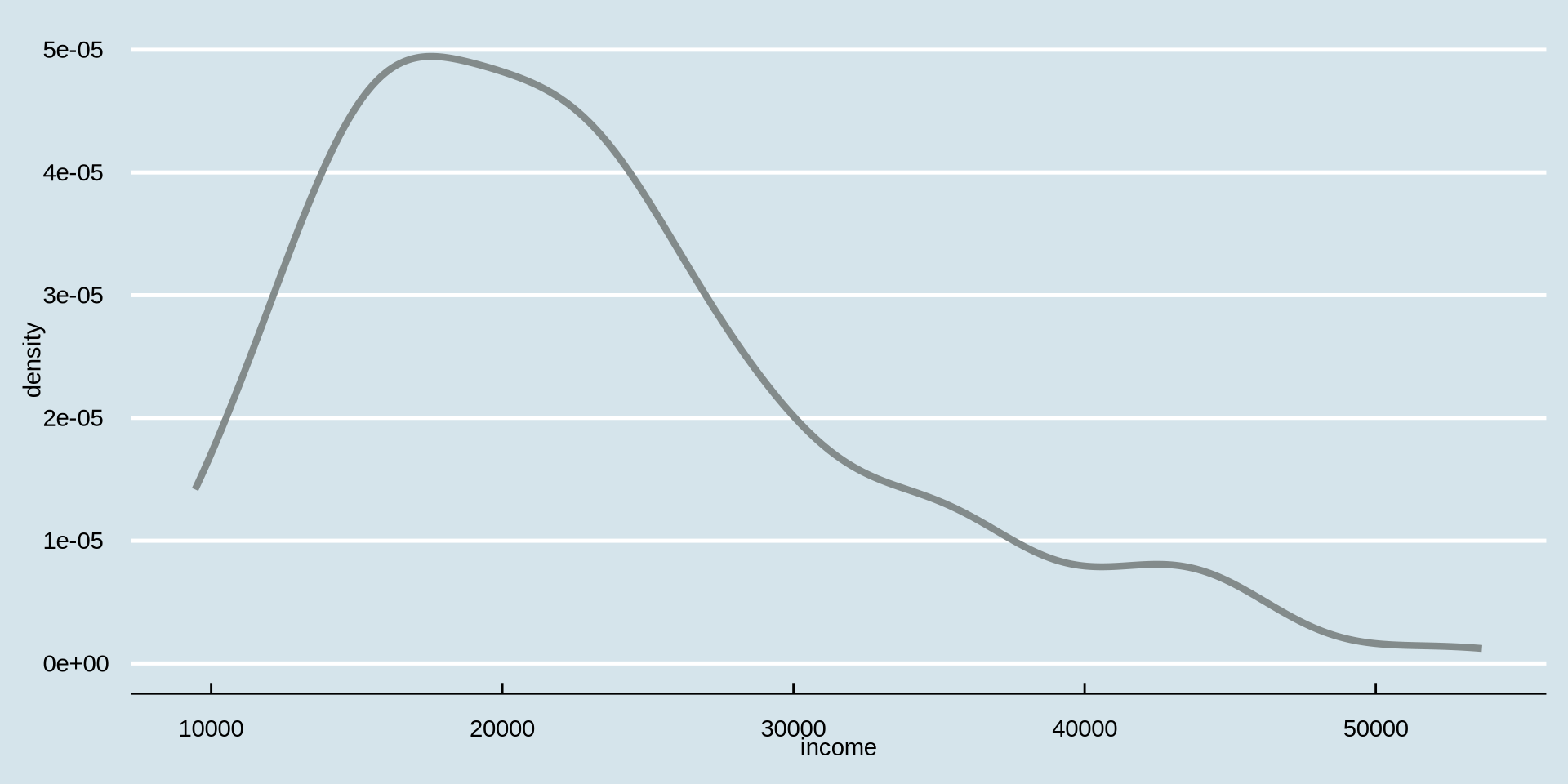
Gelir Nasıl Dağılmış?
Sürekli bir değişkenin dağılımı
Yoğunluk Grafiği
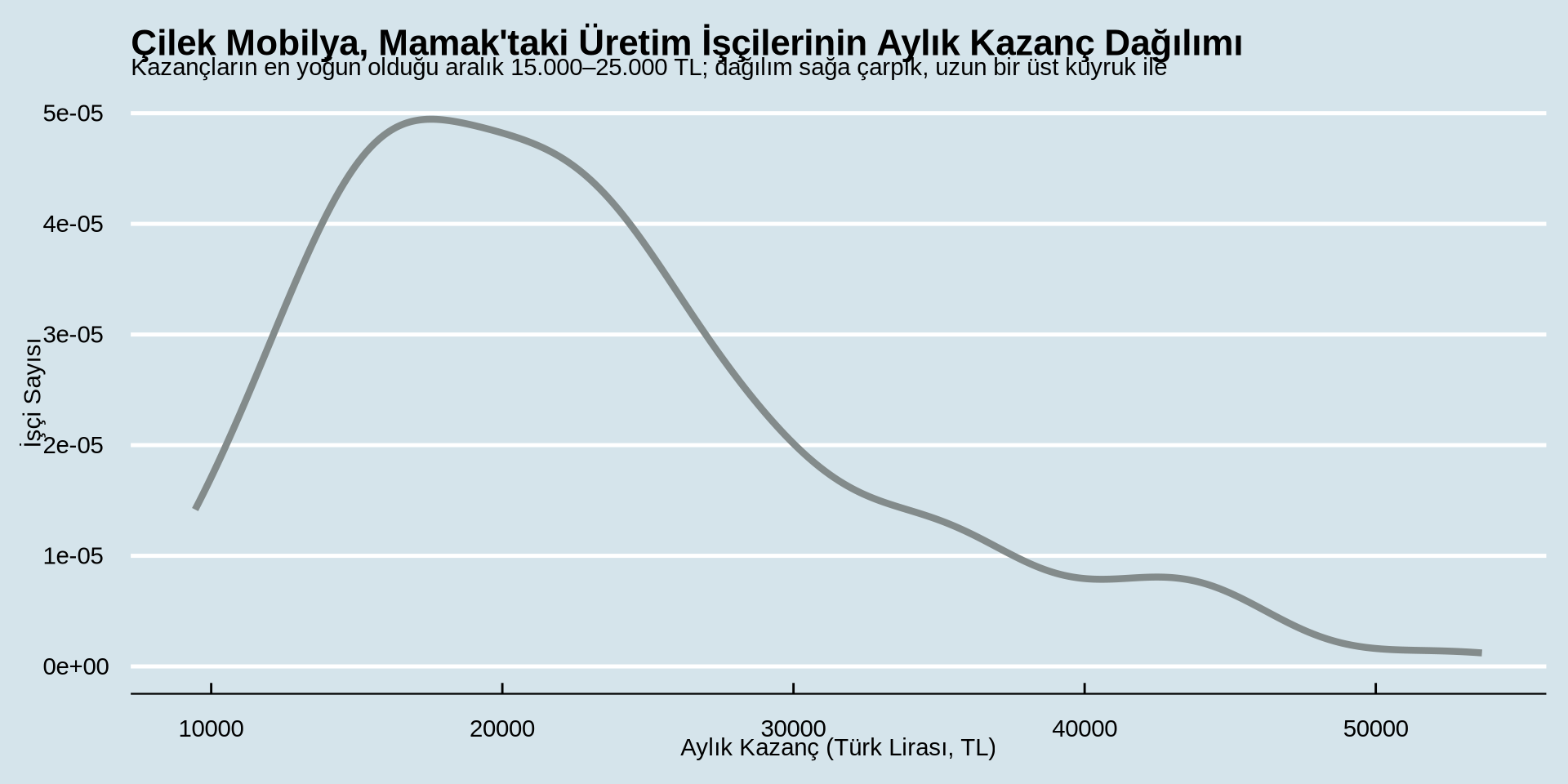
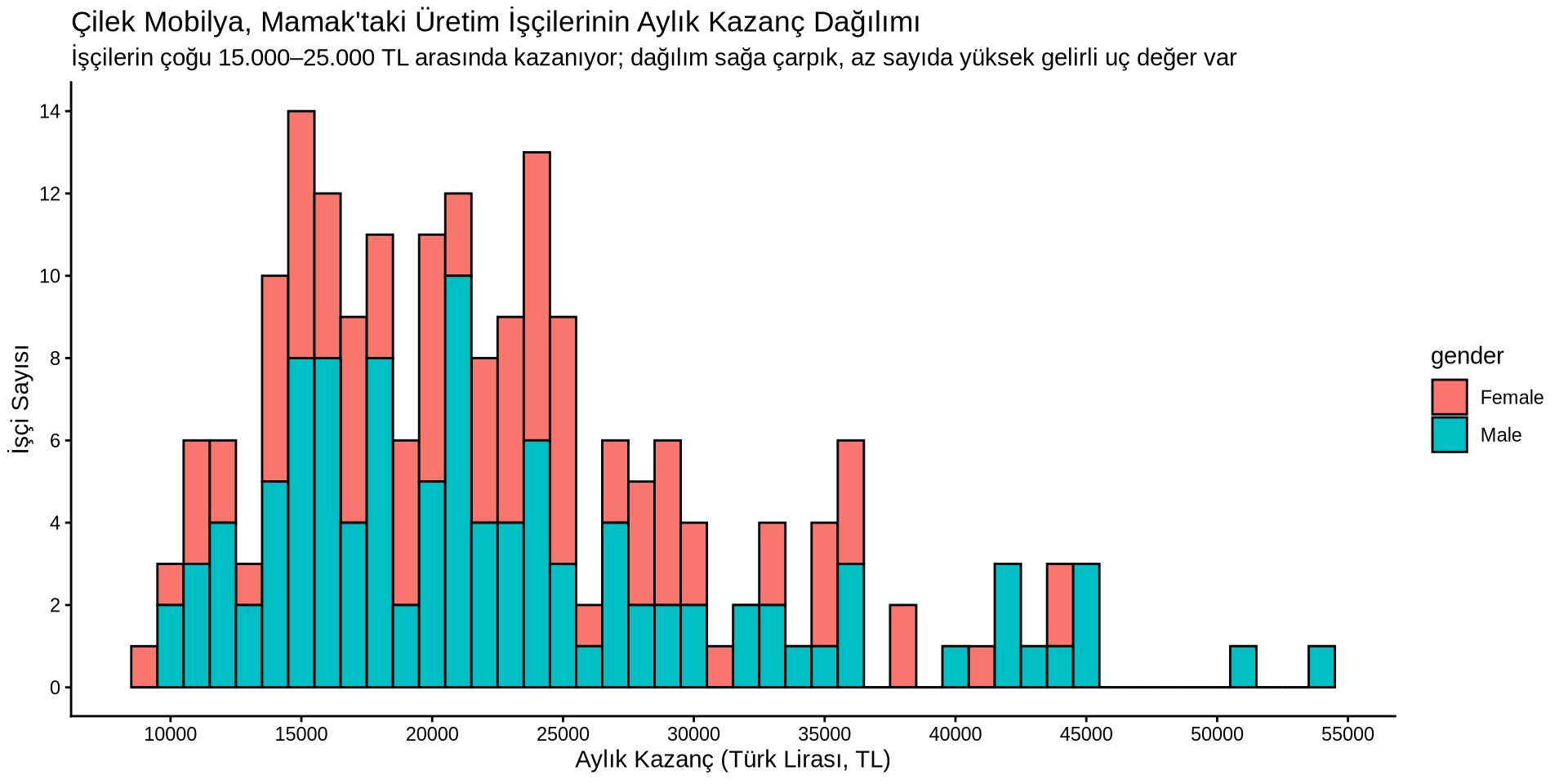
Gelir Cinsiyetler Arasında Nasıl Dağılmış?
Sürekli bir değişkenin gruba göre dağılımı
Yoğunluk Grafiği - cinsiyete göre çizgi rengini değiştir
Bu bizim kodumuz ve grafiğimizdi
earnings %>%
ggplot() +
aes(x = income) +
geom_density(color = "azure4", linewidth = 1.5) +
labs(
title = "Çilek Mobilya, Mamak'taki Üretim İşçilerinin Aylık Kazanç Dağılımı",
subtitle = "İşçilerin çoğu 15.000–25.000 TL arasında kazanıyor; dağılım sağa çarpık, az sayıda yüksek gelirli uç değer var",
x = "Aylık Kazanç (Türk Lirası, TL)",
y = "İşçi Sayısı"
) +
theme_economist()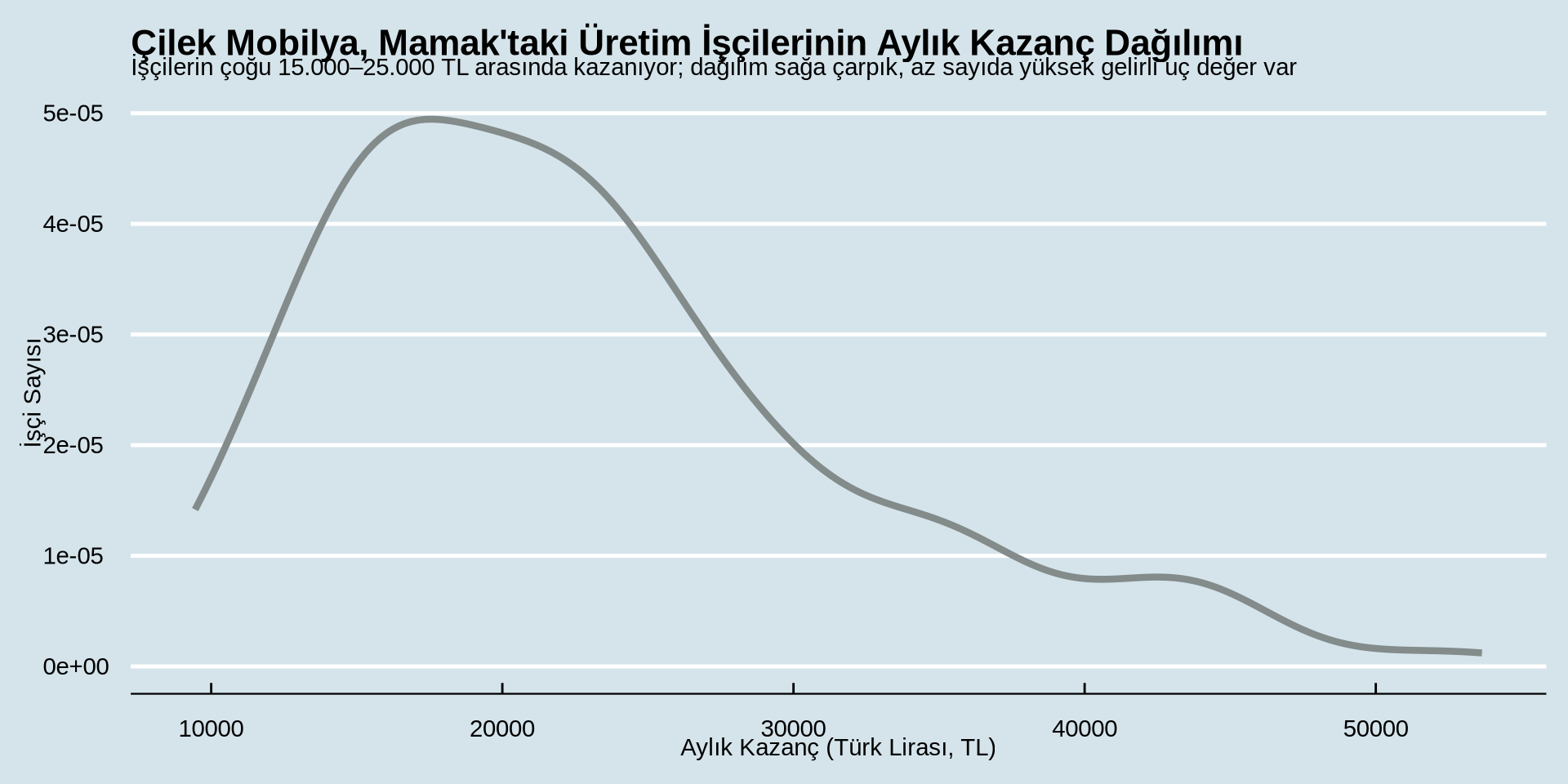
Gelir Nasıl Dağılmış?
Sürekli bir değişkenin gruba göre dağılımı
Yoğunluk Grafiği
earnings %>%
ggplot() +
aes(x = income, color = gender) +
geom_density(linewidth = 1.5) +
labs(
title = "Çilek Mobilya, Mamak'taki Üretim İşçilerinin Aylık Kazanç Dağılımı",
subtitle = "İşçilerin çoğu 15.000–25.000 TL arasında kazanıyor; dağılım sağa çarpık, az sayıda yüksek gelirli uç değer var",
x = "Aylık Kazanç (Türk Lirası, TL)",
y = "İşçi Sayısı"
) +
theme_economist()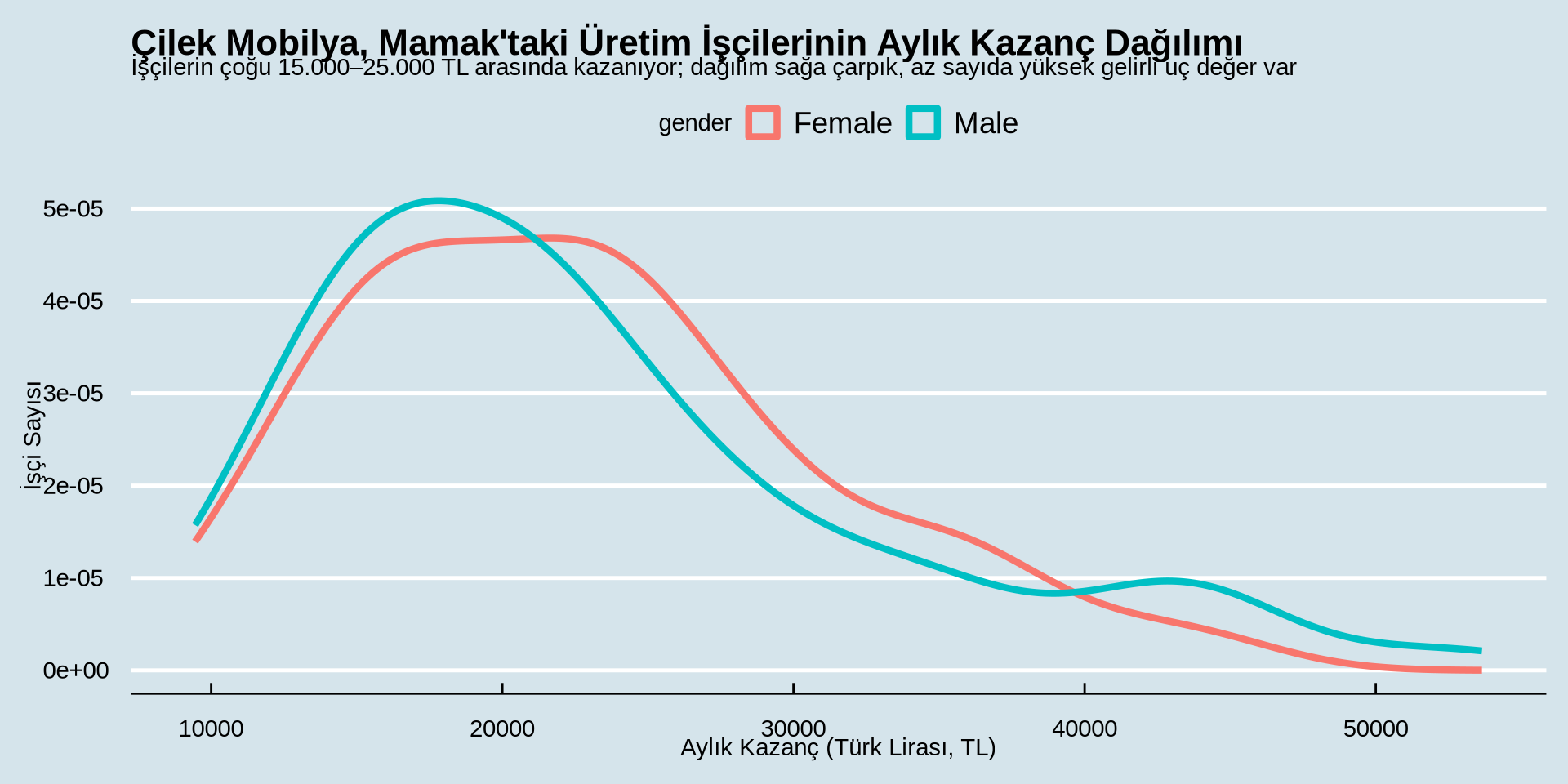
Gelir Nasıl Dağılmış?
Sürekli bir değişkenin gruba göre dağılımı
Yoğunluk Grafiği
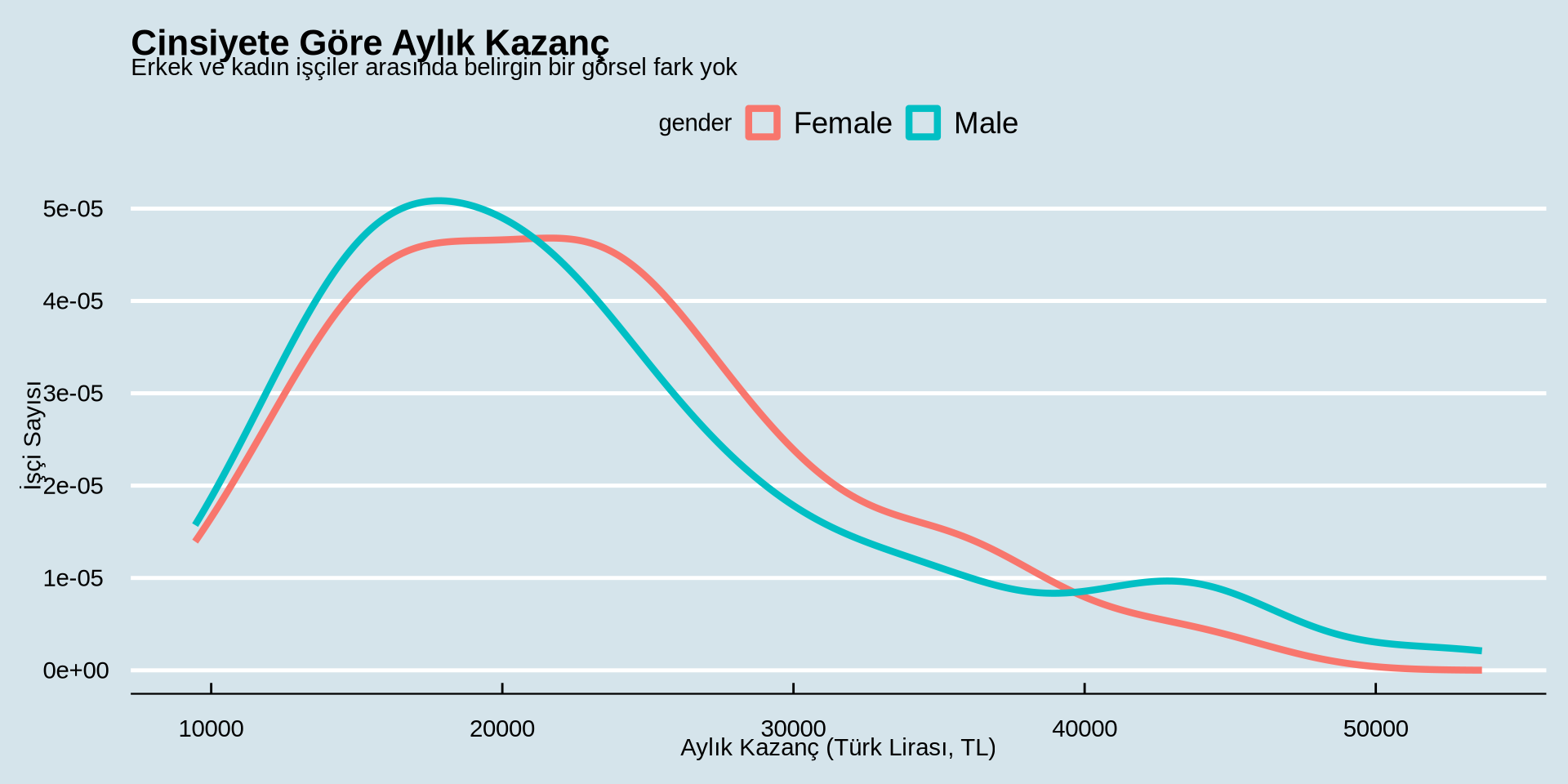
Gelir Nasıl Dağılmış?
Sürekli bir değişkenin gruba göre dağılımı
Yoğunluk Grafiği - cinsiyete göre renk türünü değiştir
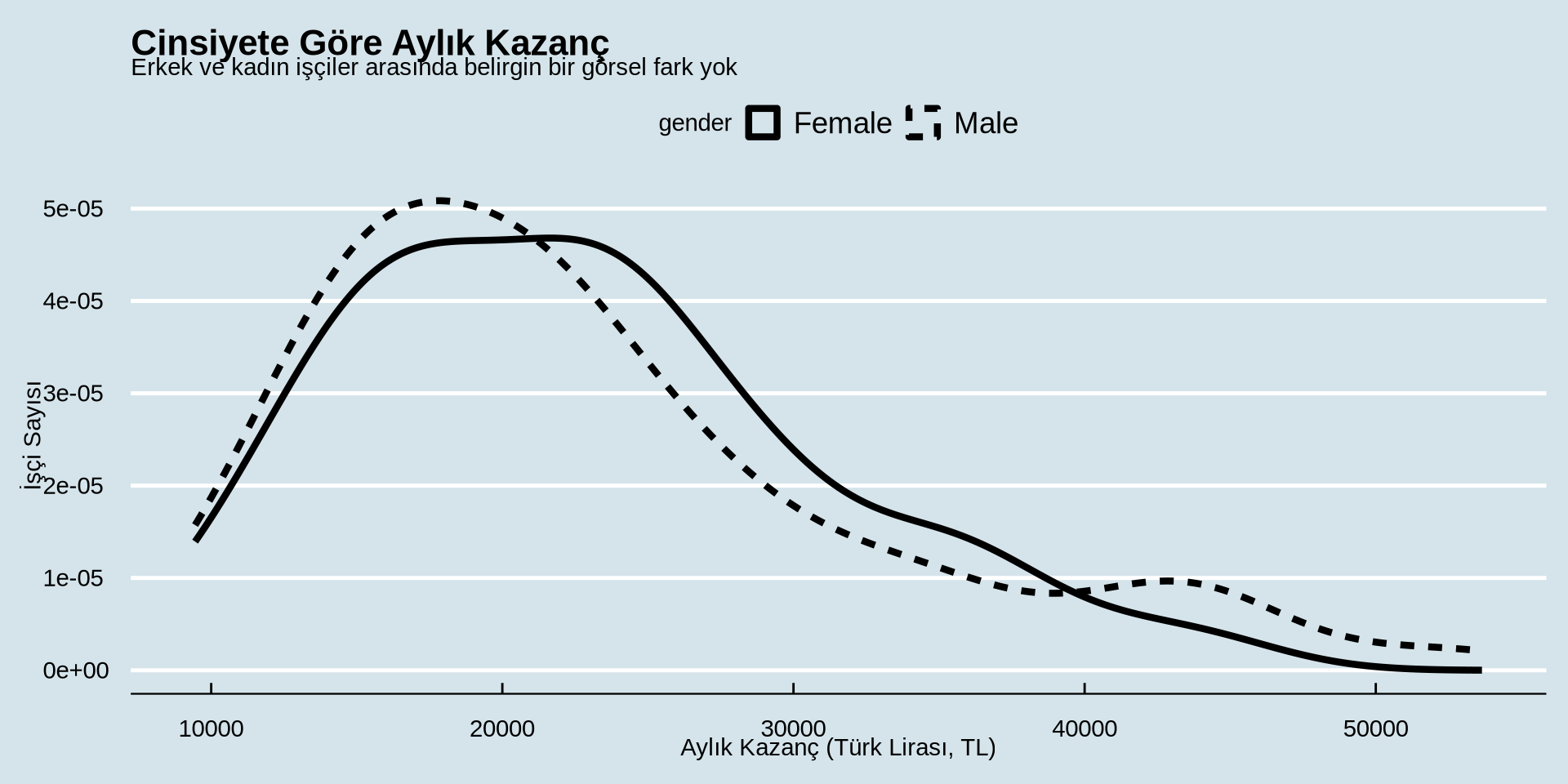
Gelir Nasıl Dağılmış?
Sürekli bir değişkenin gruba göre dağılımı
Histogram
Histogram kodumuzu hatırlıyor musunuz?
earnings %>%
ggplot() +
aes(x = income) +
geom_histogram(binwidth = 1000, fill = "lightskyblue", color = "black") +
scale_x_continuous(n.breaks = 10) +
scale_y_continuous(n.breaks = 10) +
labs(
title = "Çilek Mobilya, Mamak'taki Üretim İşçilerinin Aylık Kazanç Dağılımı",
subtitle = "İşçilerin çoğu 15.000–25.000 TL arasında kazanıyor; dağılım sağa çarpık, az sayıda yüksek gelirli uç değer var",
x = "Aylık Kazanç (Türk Lirası, TL)",
y = "İşçi Sayısı"
) +
theme_classic()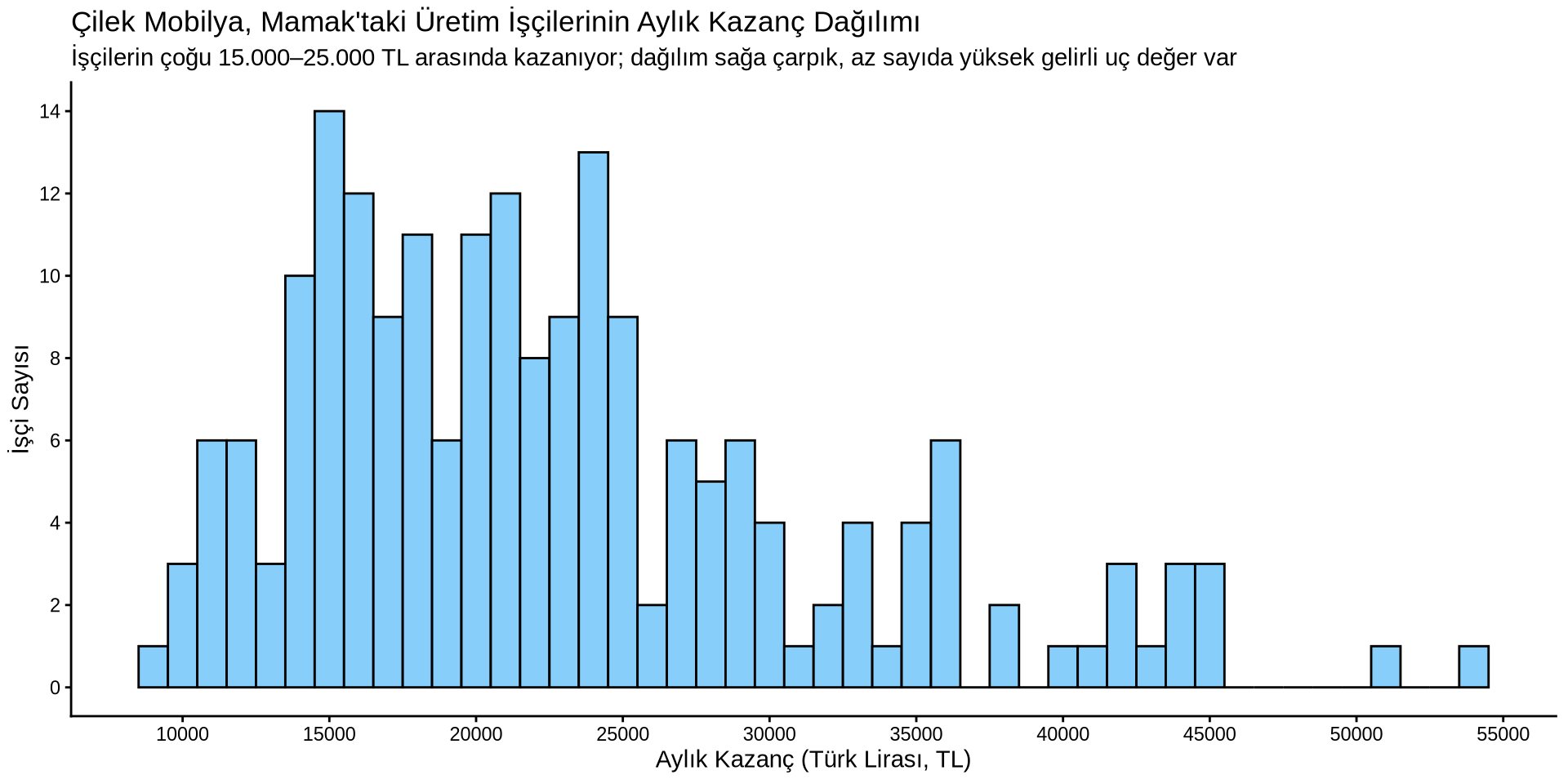
Gelir Nasıl Dağılmış?
Sürekli bir değişkenin gruba göre dağılımı
Histogram
Binleri tek bir renkle doldurmak yerine, cinsiyete göre fill yapalım. Bu arada temayı daha güzel biriyle değiştirin.
earnings %>%
ggplot() +
aes(x = income, fill = gender) +
geom_histogram(binwidth = 1000, color = "black",) +
scale_x_continuous(n.breaks = 10) +
scale_y_continuous(n.breaks = 10) +
labs(
title = "Çilek Mobilya, Mamak'taki Üretim İşçilerinin Aylık Kazanç Dağılımı",
subtitle = "İşçilerin çoğu 15.000–25.000 TL arasında kazanıyor; dağılım sağa çarpık, az sayıda yüksek gelirli uç değer var",
x = "Aylık Kazanç (Türk Lirası, TL)",
y = "İşçi Sayısı"
) +
theme_classic()